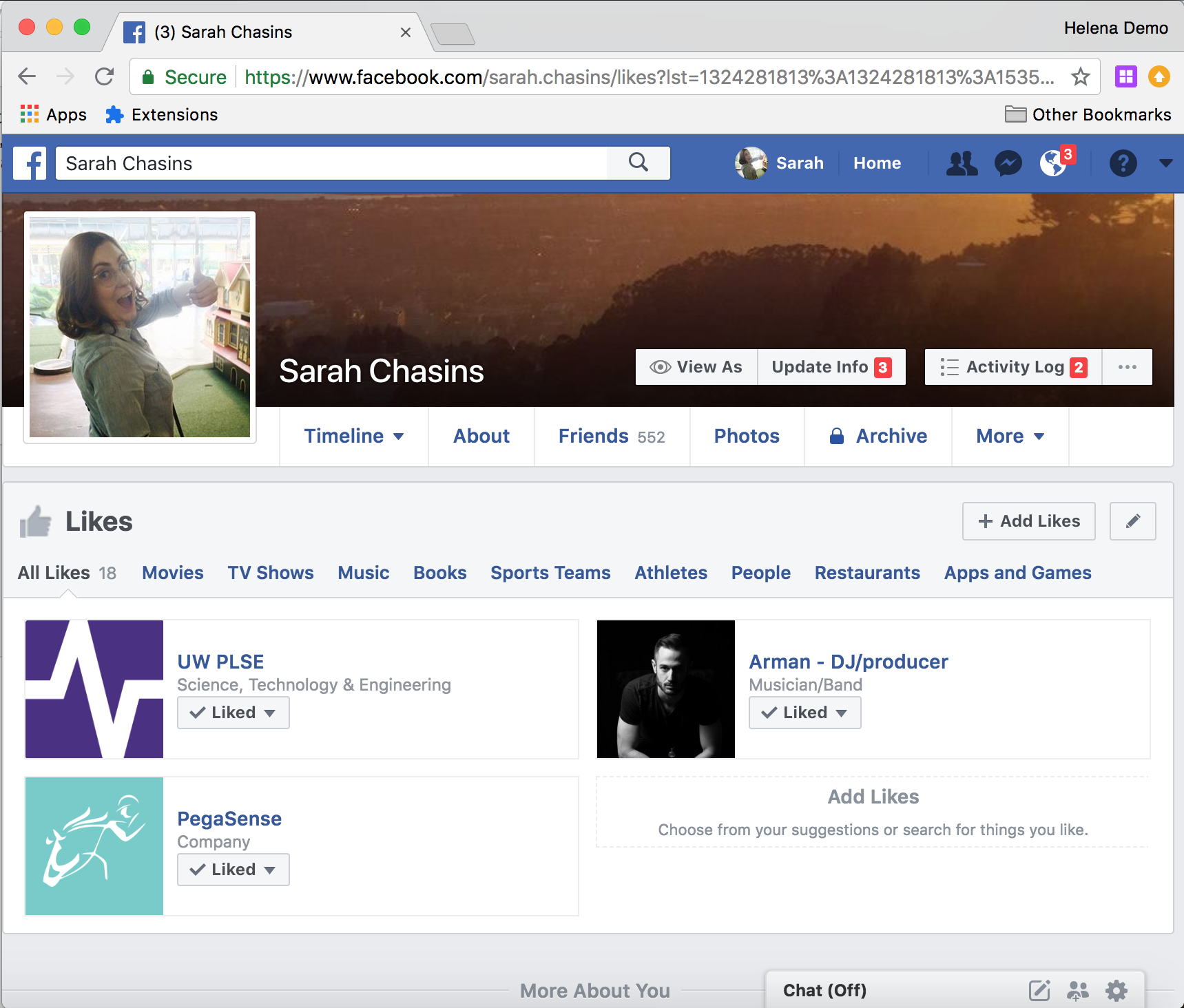
Turns out Facebook doesn’t seem to love people doing this. I couldn’t find an unlike-all button. I couldn’t even find a list where I could unlike items from the list page. As far as I could tell, I had to just click on each liked item to load its page, find where Facebook shows that I ‘like’ it on that page, hover over that element, then unlike it.
I made it through about six of these pages before I thought to myself, “What am I doing? This is extremely annoying, it’s taking forever, and I’m the author of a web automation tool that could automate this in under a minute.” So I automated it. Here’s how the process goes, using Helena to automatically unlike all my Facebook likes:
Note that at the end there, when I refresh the webpage, the items that Helena unliked have disappeared from my list of likes.
As you can see in the GIF, by the time I recorded the unliking process for this blog post, Facebook was showing me a different version of the likes page, which included ‘unlike’ buttons on the list page. Much more convenient. But back when I originally did this (that’s right, the things I’m unliking here are dummy likes - you never get to know the random things I liked as a teen!), the page that listed likes looked like the page on the left below:
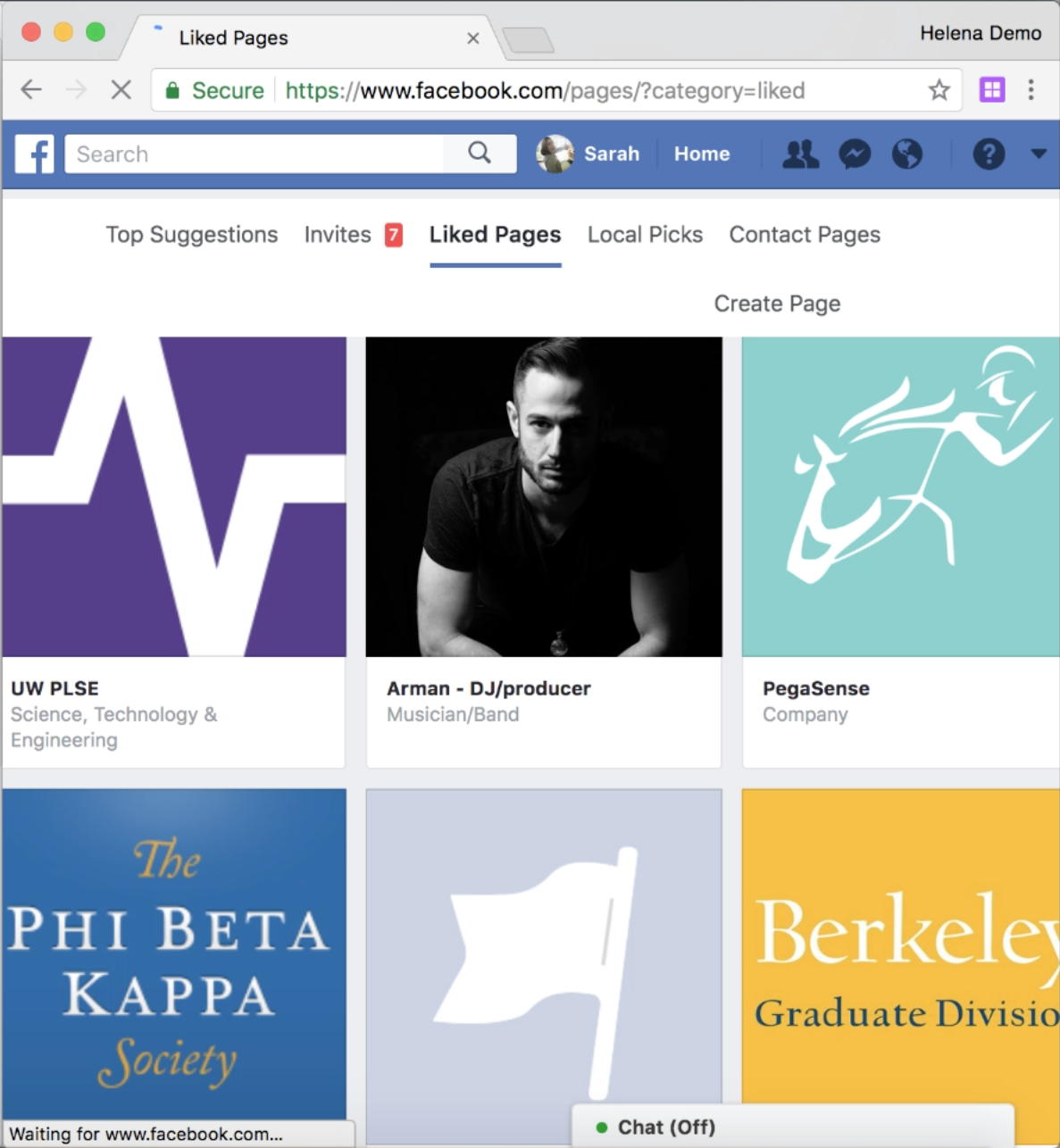 |  |
(And this is why you should write all your web automation programs with programming by demonstration, not by hand. Because wouldn’t I be sad if I spent an hour writing an automator for the old version, just to have them change the page a week later and make my program obsolete? Not that I plan to like a bunch of new things and do a fresh purge in future, but my friends do seem interested in unliking their own youthful follies.)
Anyway, the new process, now that we can unlike things from the list page goes like this:
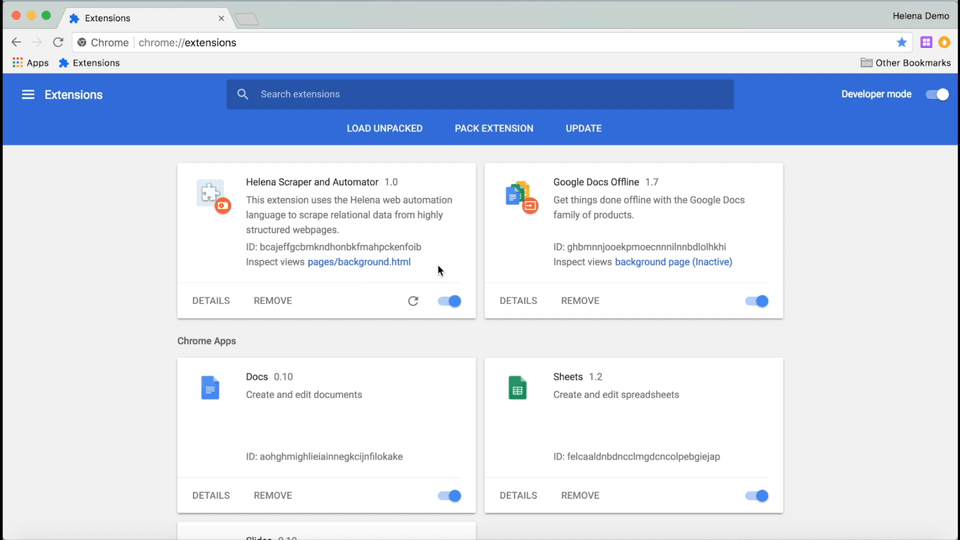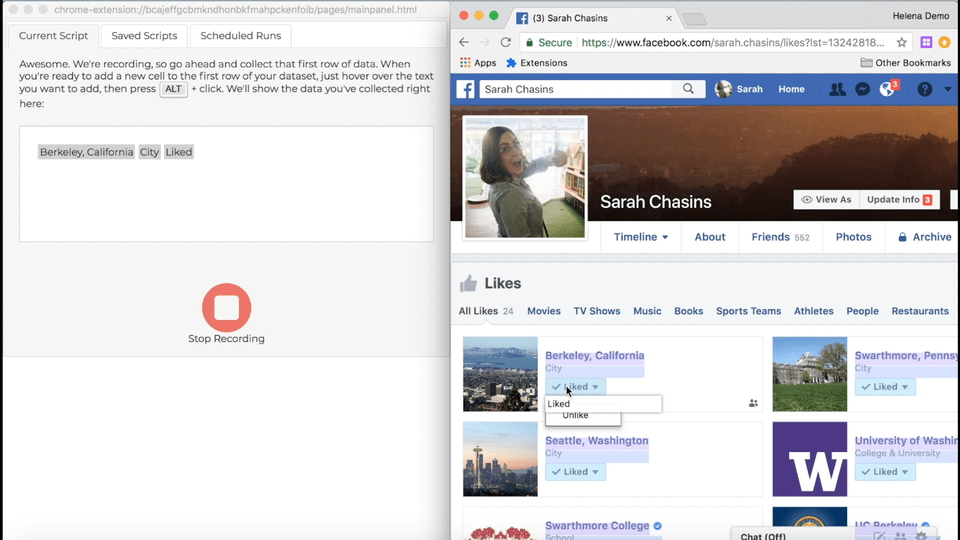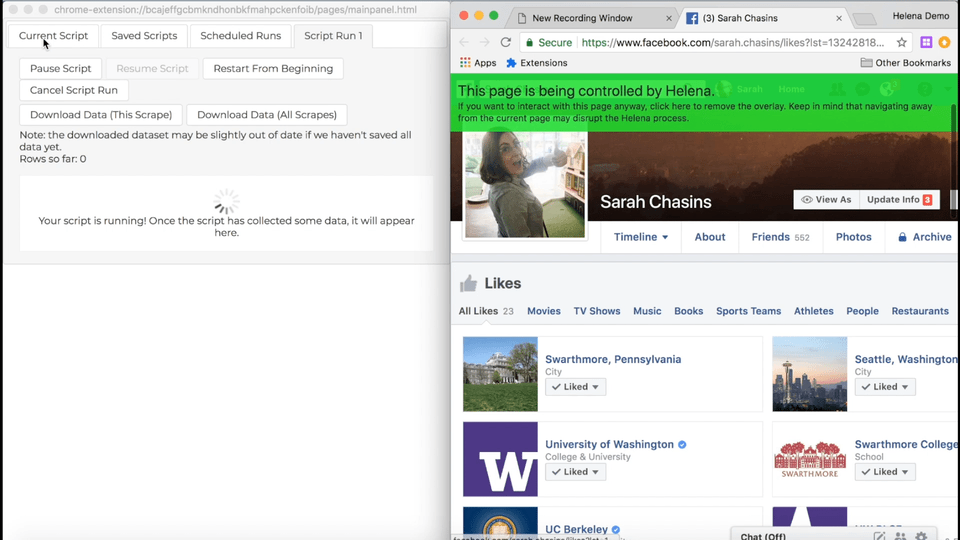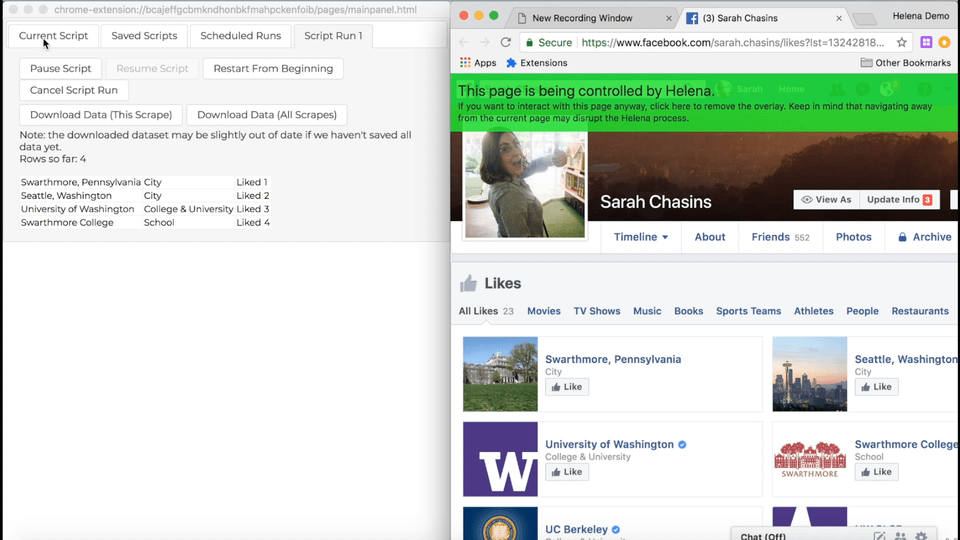
The only difference is this time we’re using that handy ‘unlike’ button on the list page, so we don’t have to follow the link to the liked page, then unlike it there. Still just as easy to do with Helena, but boy is it annoying to do by hand. Or maybe I just had too many ‘likes.’ That might be the real root of the problem.
The takeaway here is that web automation isn’t limited to scraping. Scraping is a domain in which people tend to want to automate extremely large tasks, and improvements in scraping technology can help a diverse audience of social scientists and data scientists to tackle new problems, so making web automation tools perform well for realistic scraping tasks is deeply valuable. But there’s also a whole world of other automation tasks out there. Want to download a large set of PDFs? Want to try out a whole bunch of coupon codes before you check out? Want to untag yourself from a bunch of social media posts or photos? Want to copy a bunch of papers from a spreadsheet into a web interface? Want to ‘heart’ every tweet that uses a particular phrase? Consider web automation!
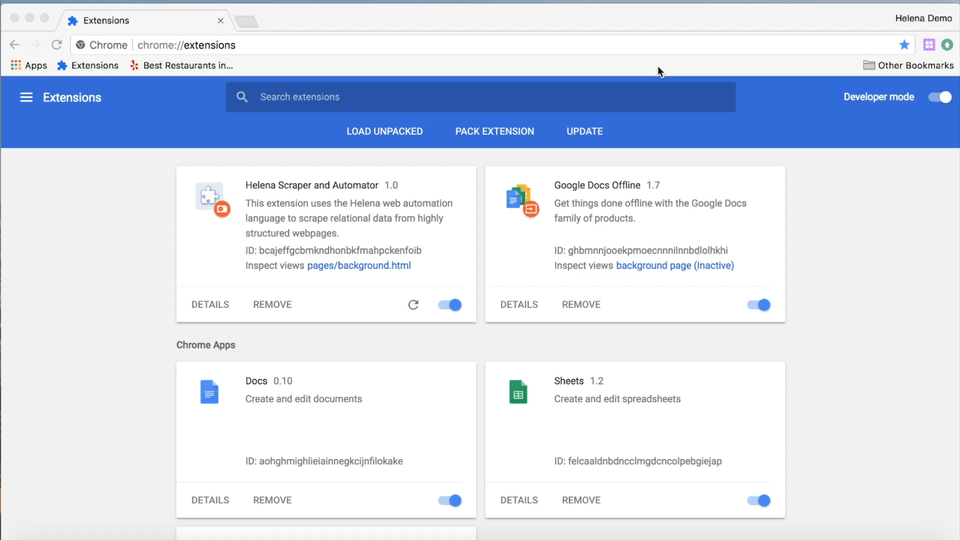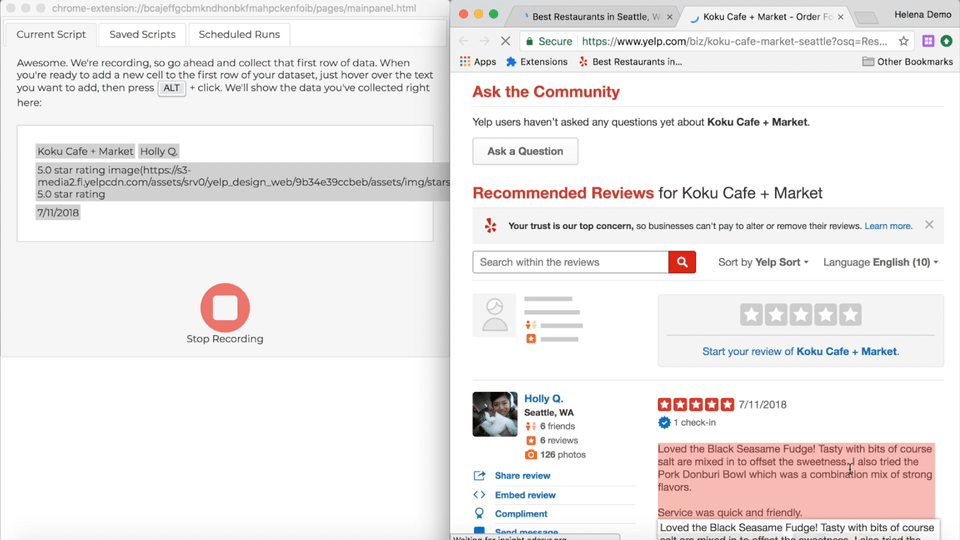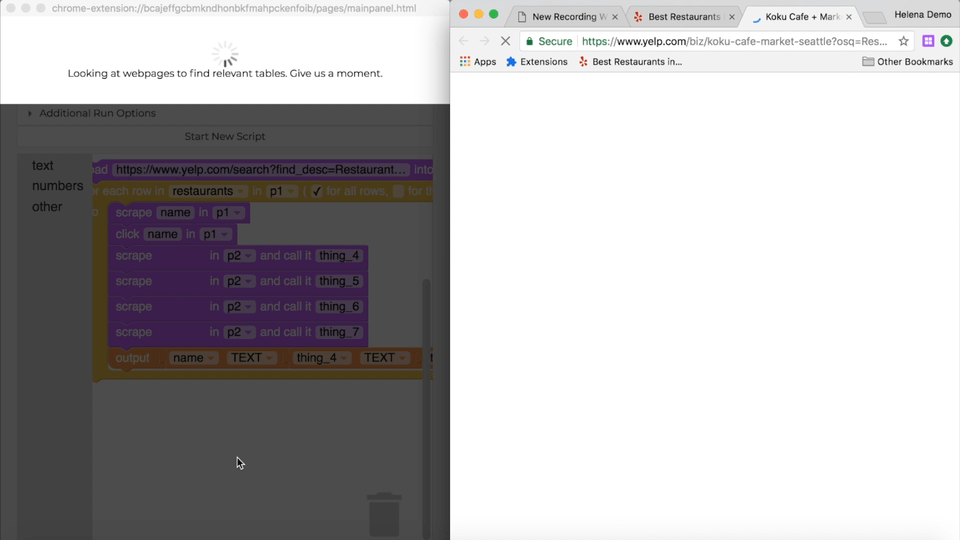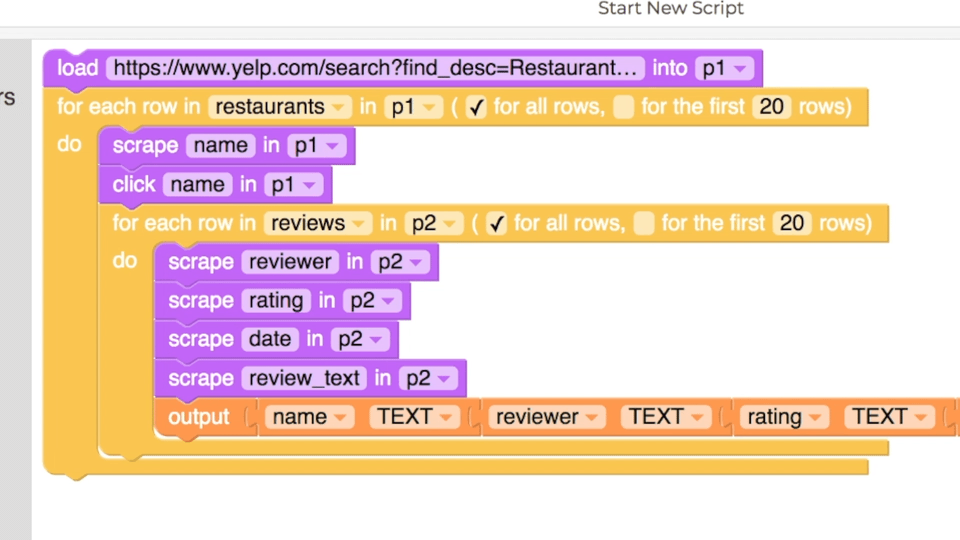
I ran into the same kind of scenario again just a couple days later, interacting with a conference management website. I’d bulk-uploaded PC members into HotCRP, but they’d all been listed as ordinary users without the PC designation. I couldn’t figure out a way to use the website to change multiple users’ PC designations at once - I found some kind of ‘Bulk Update’ link, but it seemed like the way to use it was to upload a fresh CSV with some arcane and undocumented tags attached to each user. So I just used Helena. I did a demonstration on the first user: clicked on the link to the user’s profile, clicked on the “PC Member” checkbox, then clicked on the “Save” button to save changes to the profile. Then I let Helena do the updates for the rest of the members. Here’s how it looks on HotCRP’s test conference site:
Fun fact, if you’re not careful, you might run the ‘change role to PC Member’ program on your own account, which will downgrade you from your chair/admin role, and then you won’t have the permissions to change yourself back! So here’s a fun chance to show off that we can edit our Helena programs via the blocks-based editor. Here we do the same demonstration, get the same program back from the synthesizer, then change the program to skip over users with “A L” in their names (and thus skip over the second user in the list):
In conclusion…unlike your Facebook likes.
]]>